In Gegevens inlezen en opslaan met pandas heb je geleerd hoe je gegevens vanuit verschillende typen bestanden - zoals CSV, JSON en Excel - kunt inlezen in pandas. In pandas werk je met de gegevens in een DataFrame, vergelijkbaar met een tabel. Lees die tutorial nog eens terug als je een opfrisser nodig hebt over wat een DataFrame ook alweer is.
In veel gevallen zul je niet met de hele DataFrame in één keer willen werken, maar wil je een selectie maken. Je hebt bijvoorbeeld maar enkele kolommen nodig, of juist alleen de rijen die voldoen aan een bepaalde voorwaarde. In deze tutorial leer je daarom hoe je gegevens uit een DataFrame kunt selecteren.
Voordat je begint
Om het selecteren te demonstreren, maak je gebruik van het project KNMI. Je kunt dit project bekijken op Github, zorg ervoor dat je voor deze tutorial de branchversie-3 bekijkt.
shell
cdprojects/knmi
source.venv/bin/activate# .venv\Scripts\activate.bat voor Windows
gitswitchversie-3
python-mpipinstall--upgrade-rrequirements.txt
In het KNMI-project download je data van het KNMI. Dit komt in een txt-bestand. Nadat je het tekstbestand hebt opgeslagen, schoon je het op en sla je het op als CSV-bestand, zodat er eenvoudiger mee is te werken. De data zijn maand- en jaargemiddelde temperaturen van het meetstation De Bilt.
Zorg ervoor dat je in main.py met de volgende code begint:
python
fromdataimportclean_data,download,load_dataif__name__=="__main__":# Download de gegevenstry:download()exceptrequests.exceptions.HTTPErrorase:print("Error while downloading file:",e)# Schoon de gegevens op, sla op als CSVclean_data()# Laad de gegevens in een pandas DataFramedf=load_data()
In load_data() is de volgende code te vinden:
print(df.head(),"\n")
Hiermee toon je de eerste vijf rijen van de DataFrame, voor een snelle inspectie. Je kunt daar nog de volgende instructie aan toevoegen, voor een verdere inspectie:
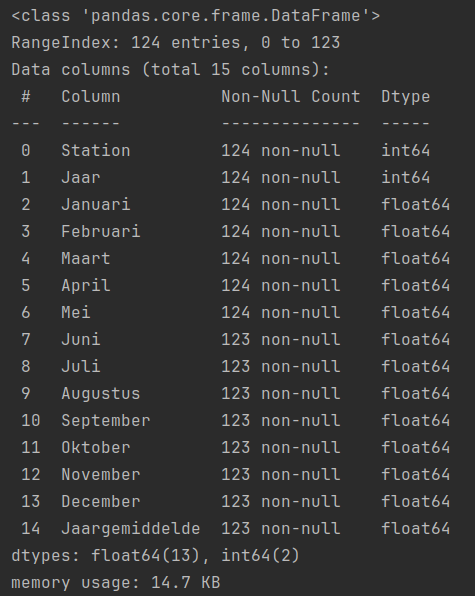
print(df.info(),"\n")
Dit toont alle aanwezige kolommen, per kolom het aantal rijen met een waarde (non-null) en het dtype. In dit geval zijn alle kolommen int64 of float64.
Plaats alle verdere code in main.py in het if __name__ == "__main__"-blok. Je kunt het downloaden en opschonen van de gegevens één keer uitvoeren, en dan (tijdelijk) uitschakelen met comments.
Kolommen selecteren
De eenvoudigste manier om een bepaalde kolom te selecteren, is met []. Om bijvoorbeeld de kolom Jaargemiddelde te selecteren:
jaargemiddelde=df["Jaargemiddelde"]
Dit is herkenbaar, omdat het lijkt op hoe je bijvoorbeeld een waarde uit een dict ophaalt op basis van de sleutel. Echter, in de documentatie van pandas raden ze dit af. Ook een andere eenvoudige manier raden ze af:
jaargemiddelde=df.Jaargemiddelde
Voor snelle inspectie is dit prima, maar voor productiecode raden ze andere manieren aan.
loc
Met .loc gebruik je labels om kolommen en rijen te selecteren. In het geval van kolommen, is de label de kolomnaam. De algemene structuur van .loc is:
df.loc[row_indexer,column_indexer]
Om één of meer kolommen te selecteren waarbij je alle rijen wilt houden, gebruik je : op de plaats van de rij-selectie. Dus om de kolom "Jaargemiddelde" te selecteren:
Zou je "Jaar" en "Jaargemiddelde" omdraaien in de lijst, dan zijn de kolommen in de resulterende DataFrame ook omgedraaid.
Je kunt ook slicing toepassen. Stel dat je alle maandkolommen wilt selecteren:
maanden=df.loc[:,"Januari":"December"]
Het is hiervoor dus wel belangrijk dat je van tevoren je gegevens hebt geïnspecteerd, zodat je weet welke kolommen je precies selecteert die tussen "Januari" en "December" liggen. Let ook op dat, in tegenstelling tot gebruikelijk in Python, de slicetot en met is, dus ook "December" wordt geselecteerd.
Filteren
Je kunt .loc ook gebruiken met een lijst van booleans om tot een selectie te komen. Maak eerst een lijst met booleans. De volgende code kijkt of de "r" in de kolomnaam voorkomt. Let op dat je niet df gebruikt (de gehele dataset), maar maanden, de hiervoor aangemaakte DataFrame met enkel de maanden kolommen.
Let er altijd op dat de lengte van de lijst met booleans even lang is als het aantal kolommen. In dit geval bevat maanden 12 kolommen, en moet de lijst met booleans dus ook 12 lang zijn. Je kunt het zo zien: de lijst met booleans schuif je over de kolomnamen heen. Alle kolommen met True selecteer je (blijven behouden).
Rijen selecteren
Tot dusver heb je .loc gebruikt om kolommen te selecteren, waarbij je alle rijen steeds behield. Je kunt .loc ook gebruiken om bepaalde rijen te selecteren. Dit werkt exact hetzelfde als bij de kolommen, maar dan als eerste argument in .loc[], voor de komma.
Om bijvoorbeeld de eerste rij te selecteren, gebruik je df.loc[0, :]. In dit geval zijn de labels 0...n, maar let op dat de label niet hetzelfde is als de index bij bijvoorbeeld een Python lijst. In het volgende voorbeeld stel je de index in op de waarden van de kolom "Jaar".
df.set_index("Jaar",inplace=True)
Station Januari Februari ... November December Jaargemiddelde
Jaar ...
1901 260 -0.3 -0.9 ... 5.2 3.0 8.7
1902 260 4.7 -0.3 ... 3.7 0.8 8.2
1903 260 3.0 5.7 ... 5.6 0.9 9.2
1904 260 0.8 3.0 ... 5.5 4.0 8.9
1905 260 1.3 3.6 ... 3.8 2.4 8.7
Wil je nu de eerste rij selecteren - het eerste jaar dus -, dan gebruik je df.loc[1901, :]. Meerdere rijen selecteren werkt hetzelfde als bij meerdere kolommen selecteren. Je geeft een lijst op met de gewenste rijen, of een slice.
Ook nu kun je weer een lijst met booleans gebruiken om de rijen te filteren. Stel dat je alleen de jaren wilt overhouden waar de gemiddelde temperatuur in januari hoger dan 0 graden was:
De lijst met booleans moet net zo lang zijn als het aantal rijen van de DataFrame. In de eerste stap selecteer je dus eerst de kolom "Januari" met df.loc[:, "Januari"]. Vervolgens gebruik je > 0 om voor elke rij te kijken of de waarde groter is dan nul. Per rij levert dit dus True of False op. Deze lijst met booleans voeg je in de tweede stap toe aan .loc[], op de plaats van de te selecteren rijen. Ook hier kun je het weer zien alsof je de lijst met booleans over de rij-labels heen schuift en alleen de rijen met True selecteert.
Alleen rijen
Overigens is het zo dat als je alle kolommen wilt behouden, je de : mag weglaten. Dit levert dus hetzelfde resultaat op:
Ofwel: gebruik je maar één argument in .loc[], dan maak je automatisch selecties van de rijen.
Rijen en kolommen filteren
Je hebt nu steeds op alleen de kolommen óf alleen de rijen gewerkt. Maar .loc[] staat uiteraard toe dat je tegelijkertijd kolommen en rijen selecteert. Bijvoorbeeld, alleen de gegevens van het eerste kwartaal voor de jaren 1980-1990:
q1_80=df.loc[1980:1990,"Januari":"Maart"]
Of alleen het jaargemiddelde voor de jaren waar het jaargemiddelde boven de 10 graden lag:
Met .loc kom je een heel eind, maar er zijn ook andere methodes om gegevens te selecteren.
iloc
Net als .loc, kun je .iloc gebruiken om kolommen en/of rijen te selecteren. De werking is vrijwel hetzelfde, met het grote verschil dat je bij .iloc de integer gebaseerde positie gebruikt, in plaats van de labels. Je kunt .iloc vergelijken met het ophalen van items uit een lijst, waar je ook de integer gebaseerde index gebruikt. Net als bij een lijst, begin je bij .iloc ook met tellen bij 0.
Dus om de eerste drie jaren op te halen gebruik je .loc met labels, of .iloc met de integer gebaseerde index. (NB: je had de index op het jaartal gezet, weet je nog?)
eerste_drie_jaren=df.loc[1901:1903]# Let op: 1903 is inclusiefeerste_drie_jaren=df.iloc[0:3]# Let op: 3 is exclusief
Je ziet dat een groot - en eerlijk gezegd verwarrend - verschil is, dat bij .loc zowel de start- als eindpositie inclusief zijn. Bij .iloc is alleen de startpositie inclusief, de eindpositie is exclusief.
at en iat
Heb je de waarde uit een enkele cel nodig, dan kun je dat uiteraard met .loc of .iloc doen. Maar voor deze speciale situatie zijn ook .at en iat beschikbaar. Ze werken hetzelfde als .loc en .iloc, met het verschil dat je dus maar één rij en één kolom kunt opgeven. Dit zorgt ervoor dat het een iets snellere handeling is.
jan_2020=df.at[2020,"Januari"]
Conclusie
Als je net met pandas begint, kan het selecteren van de juiste gegevens uit een DataFrame lastig zijn. De regels van .loc en aanverwanten zijn misschien niet helemaal intuïtief, bijvoorbeeld dat je .loc[] gebruikt in plaats van .loc(). Of dat bij een slice de eindwaarde óók inclusief is (maar bij .iloc dan weer niet).
Het is even wennen misschien. Daarom is het wel aan te raden om er goed mee te oefenen, want het zal zelden zijn dat je de hele DataFrame nodig hebt.
Alle code voorbeelden en voorbeeldbestanden van dit project zijn ook op Github te bekijken.
Over de auteur
Erwin Matijsen
Erwin is de oprichter van python-cursus.nl. In allerlei rollen heeft hij Python ingezet, van het eenvoudiger maken van zijn werk tot het opleveren van complete (web)applicaties. Met vrouw en kinderen woont hij in Havelte (Drenthe), midden in de prachtige natuur. Daar wandelt hij graag, zeker ook omdat de beste ingevingen tijdens een wandeling - weg van de computer - lijken te komen.
Vragen, opmerkingen?
Heb je vragen, opmerkingen, suggesties of tips naar aanleiding van deze blog?
Neem dan contact met ons op, of laat het weten via
Mastodon of
LinkedIN.