31 januari 2024 Erwin Matijsen
Geplaatst in Tutorial
Als je vaak dezelfde gegevens download om mee te werken, bijvoorbeeld van een API, is het handig om dit te automatiseren.
In deze tutorial leer je hoe je requests gebruikt om gegevens te downloaden, ze in een CSV op te slaan en ze vervolgens opschoont.
Het project
In dit project download je data van het KNMI. Dit komt in een txt-bestand. Nadat je het tekstbestand hebt opgeslagen, schoon je het op en sla je het op als CSV-bestand, zodat er eenvoudiger mee is te werken. De data zijn maand- en jaargemiddelde temperaturen van het meetstation De Bilt. De url is:
Lees voordat je begint nog eens Werken met pip en venv door als een opfrisser nodig hebt over
hoe je een virtual environment aanmaakt en daarin packages installeert.
Maak vervolgens een nieuw project aan en installeer requests:
shell
cdprojects
mkdirknmi&&cdknmi
python-mvenv.venv
source.venv/bin/activate# .venv\Scripts\activate.bat voor Windows
python-mpipinstallrequests
python-mpipfreeze>requirements.txt
Data downloaden met requests
requests is een package dat het werken met urls eenvoudig maakt. In hun eigen woorden:
Requests is an elegant and simple HTTP library for Python, built for human beings.
Maak een main.py aan maak daarin een eenvoudige download-functie.
main.py
importrequestsURL="https://cdn.knmi.nl/knmi/map/page/klimatologie/gegevens/maandgegevens/mndgeg_260_tg.txt"TXT="knmi.txt"defdownload():response=requests.get(URL)# Als de HTTP-code 400 of hoger is, zal er een uitzondering worden opgeworpenresponse.raise_for_status()# Sla het bestand opwithopen(TXT,"w",encoding="utf-8")asfile:file.write(response.text)
Je ziet hoe eenvoudig requests werkt. Met response.raise_for_status() controleer je of de HTTP-code lager is dan 400.
Zo niet, dan wordt er een uitzondering opgeworpen.
Alles in de 4XX en 5XX reeks betekent namelijk dat er iets niet goed ging. Zie de lijst met HTTP-codes voor meer informatie.
Je slaat het bestand op de huidige locatie op (dus naast main.py). Met "w" geef je aan dat je het bestand wilt schrijven. Let op: als het bestand al bestaat, zal het hierdoor worden overschreven!
Voeg tot slot onderaan in main.py het volgende toe:
main.py
if__name__=="__main__":download()
Je kunt het bestand nu uitvoeren in je shell met python main.py. Als het goed is, is er nu een bestand knmi.txt opgeslagen. Open het bestand met een teksteditor naar keuze om te inspecteren.
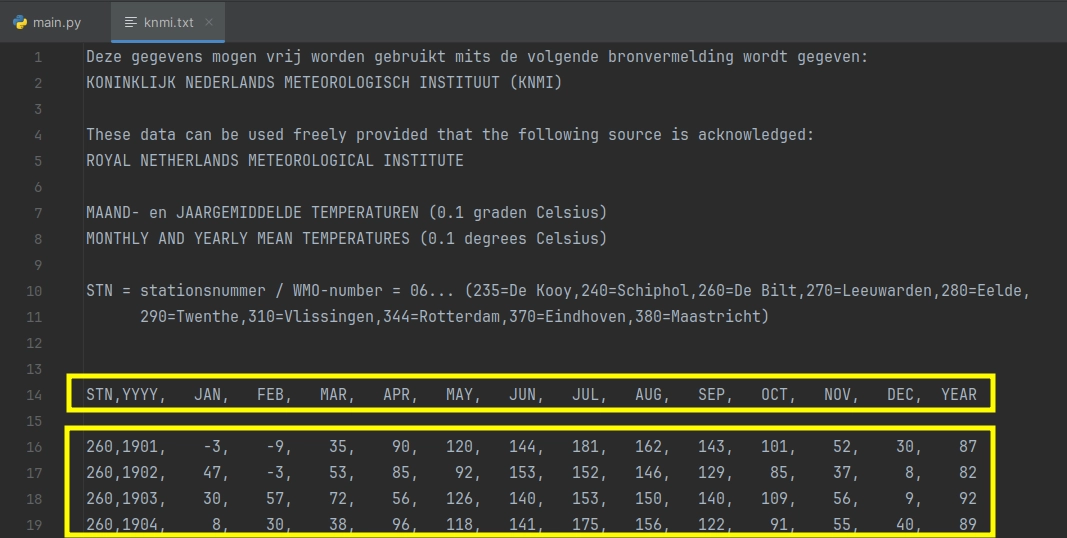
Je ziet dat het tekstbestand de koppen (eerste gele markering) en gegevens (tweede gele markering) bevat, maar begint met een toelichtende tekst.
Als je geautomatiseerd wilt werken met de gegevens, heb je deze tekst niet nodig. Tijd voor de volgende stap!
Het bestand opschonen
Er zijn drie problemen met het tekstbestand.
Ten eerste de al eerder genoemde toelichtende tekst, die heb je niet nodig. Ten tweede is er een lege regel (niet heel erg, maar nu je toch bezig bent...). En tot slot is het bestand netjes opgemaakt in kolommen, waardoor er veel spaties zijn toegevoegd. Zou je het zo omzetten naar CSV, dan zouden die spaties onderdeel worden van de gegevens.
Uiteindelijk wil je een regel alleen behouden als het de koppen bevat óf als het de gegevens bevat. De gegevens wil je opschonen door de spaties te verwijderen.
Maak een functie clean_data aan in main.py:
main.py
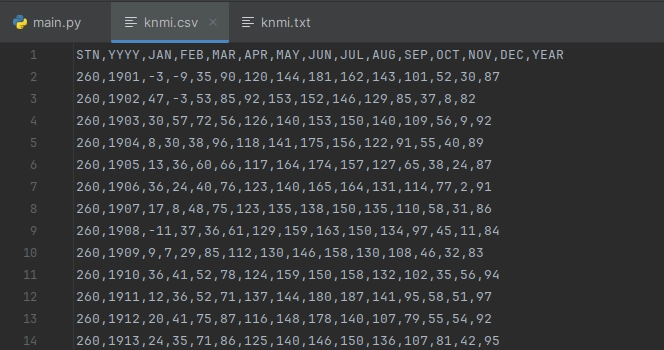
# ...TXT="knmi.txt"CSV="knmi.csv"# ...defclean_data():# Open het tekstbestandwithopen(TXT,"r",encoding="utf-8")asfile:lines=[]forlineinfile:# Behoud alleen de koppen en de rijen met gegevensifline.startswith("STN,YYYY")orline.startswith("260"):# Verwijder spatieslines.append(line.replace(" ",""))# En sla op als CSV-bestandwithopen(CSV,"w",encoding="utf-8")asfile:file.writelines(lines)# ....
Met deze functie behoud je alleen de regels die relevant zijn en schrijf je ze naar een CSV-bestand. Na het openen van het tekstbestand maak je een lege list aan,
waarin je de gewenste regels gaat toevoegen.
Een regel wil je alleen behouden als het de koppen bevat (begint met "STN,YYYY") of als het de gegevens bevat (begint met "260").
Als dit zo is, voeg je de regel toe aan lines, nadat je de spaties hebt verwijderd met line.replace(" ", """).
STN,YYYY?
Kun je ook bedenken waarom we testen op "STN,YYYY" om de regel met koppen te bewaren, en niet simpelweg op "STN"?
Tot slot maak je een nieuw CSV-bestand aan in schrijf-modus. Je schrijft met file.writelines(lines) alle regels naar het bestand, en klaar!
Voeg clean_data toe aan het if __name__ == __main__ blok.
Voer het weer uit vanuit je shell met python main.py. Open het bestand in een teksteditor om te bekijken.
Je ziet een netjes komma-gescheiden bestand. Je kunt het nu ook openen in een spreadsheet programma zoals Microsoft Excel of LibreOffice Calc om het verder te inspecteren.
Conclusie
Je hebt geleerd dat je met een klein Python-script eenvoudig gegevens kunt downloaden met requests en ze vervolgens kunt opschonen.
In dit voorbeeld worden de gegevens elke maand bijgewerkt. Met een eenvoudige python main.py download je zo de laatste gegevens en is het klaar voor gebruik.
Uiteraard kun je het script naar eigen inzicht uitbreiden of aanpassen, bijvoorbeeld door de bestanden een naam met de huidige datum erin mee te geven of een paar
statistieken te draaien.
Succes!
Over de auteur
Erwin Matijsen
Erwin is de oprichter van python-cursus.nl. In allerlei rollen heeft hij Python ingezet, van het eenvoudiger maken van zijn werk tot het opleveren van complete (web)applicaties. Met vrouw en kinderen woont hij in Havelte (Drenthe), midden in de prachtige natuur. Daar wandelt hij graag, zeker ook omdat de beste ingevingen tijdens een wandeling - weg van de computer - lijken te komen.
Vragen, opmerkingen?
Heb je vragen, opmerkingen, suggesties of tips naar aanleiding van deze blog?
Neem dan contact met ons op, of laat het weten via
Mastodon of
LinkedIN.